Capability URLs grant access to a resource to anyone who has the URL. There are particular application design patterns for which this is useful as they remove the necessity for users to log in to a site and are easily delegated to others. But their use can open up some security issues. URLs are not generally be kept secret, and there are various routes through which capability URLs can leak into unintended hands. This document provides some good practices for web developers who wish to incorporate capability URLs into their applications, to minimise these risks.
Status of This Document
This section describes the status of this document at the time of its publication.
Other documents may supersede this document. A list of current W3C publications and the
latest revision of this technical report can be found in the W3C technical reports index at
http://www.w3.org/TR/.
This is a proposed Working Draft, which is intended to eventually be published as a TAG Finding. It does not contain any normative content (eg about implementation compliance), only advice for developers.
Publication as an Editor's Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or obsoleted by other
documents at any time. It is inappropriate to cite this document as other than work in
progress.
There are two broad methods of controlling access to information that is published on the web:
the server can have access control measures that require people accessing the content to provide the correct token(s) (such as a password or cookie) before the content is accessible
the information can be published at an obscure or unguessable URL, and links to it only provided to people who have permission to access it
The URLs used in the second method are known as capability URLs: an agent who possesses the URL is given the capability to access the information.
These methods of controlling access can be used in combination. For example, a session-specific token within the URL created by a form submission (a type of capability URL) helps to protect against cross-site request forgery where third-party pages can take advantage of the fact that a user has the necessary cookie to access a target page.
This document describes:
examples where capability URLs are used on the web today
advantages and disadvantages of using capability URLs to control access to content
design considerations when creating websites that use capability URLs
areas of technical development to support the use of capability URLs
2. Example Capability URLs
Capability URLs are in widespread use. This section contains examples from the web where capability URLs are used.
2.1 Password Resets
When a user forgets their password to access a site, the site cannot simply tell them what their password is as this would require the site to store and transmit their password as plain text, which is extremely insecure.
The pattern that is usually used instead is that the user is sent an email that contains a link that provides the user who has received that link with enough permissions to reset their password. This example is from Dropbox:
Example 1
Your Dropbox password recently expired. You can reset it here.
In this case the capability URL is https://www.dropbox.com/l/Q8eJH22ft0ckDJDeff1Do10/password_reset. Anyone accessing this link (before it expires) is able to change the password for the user with whom the capability URL is associated.
2.2 Second Life
Reg API capabilities represent permissions to perform certain actions.
Within the Second Life API, user agents aren't required to provide credentials with each action that they wish to take. Instead, they submit a single form with a username and password and the response contains a set of capability URLs for different capabilities. For example:
The documentation provides two guidelines for using these capability URLs:
Do not hard-code your capabilities URLs. Either code your capabilities URLs as constants, or better yet, obtain them at run-time. Capability URLs will expire eventually, so fresh ones are always better.
Keep your capability URLs secret! The capabilities granted to you are only meant for you. A capability URL is sensitive much like a password. Moreover, Linden Lab tracks the use of each capability.
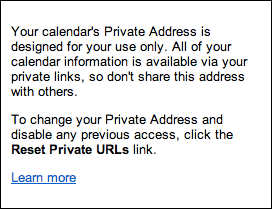
Google Calendar provides Private Addresses for XML and iCalendar formats of a calendar. These can be used by anyone within a feed reader or a calendar programme to provide access to the calendar, but users are warned "Your calendar's Private Address was designed for your use only, so be sure not to share this address with others." (from About the 'Private Address').
The help associated with Private Addresses similarly warns against sharing the URLs with others:
Fig. 3Help associated with Private Address in Google Calendar
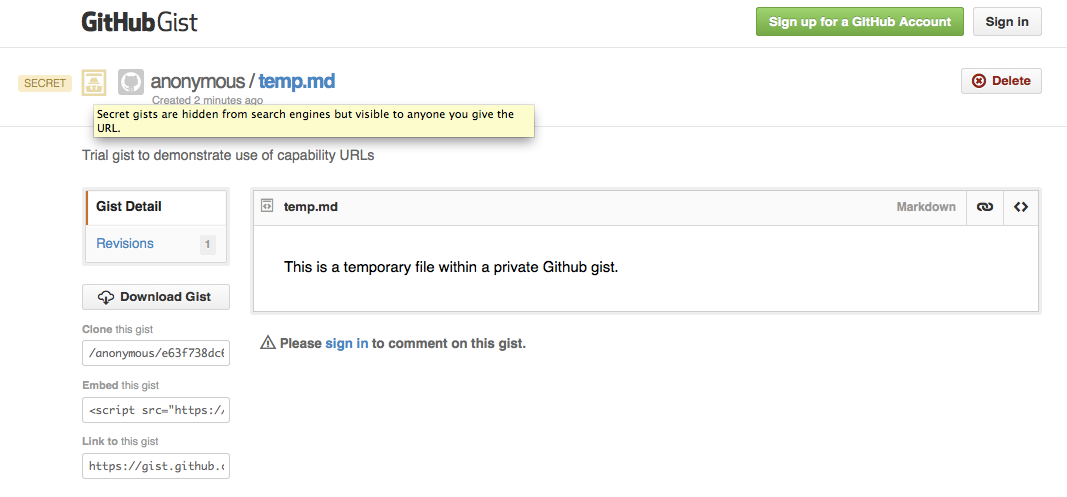
2.4 Github Gists
GitHub Gists support sharing and discussing versioned code and other files with other people. These can be created anonymously, and can be kept private. Access to private Gists is provided simply through sharing the URL for the Gist.
Fig. 4A secret GitHub Gist
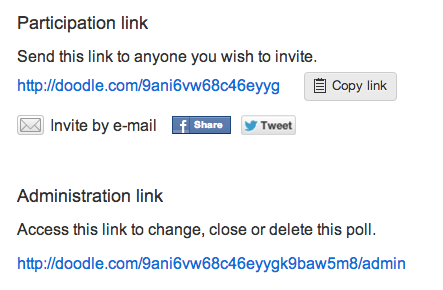
2.5 Doodle polls
Doodle enables users to create polls that can be accessed through URLs without users logging in. The URLs are provided to the administrator of the poll within the browser and through email. For example:
Fig. 5Doodle page for a new poll
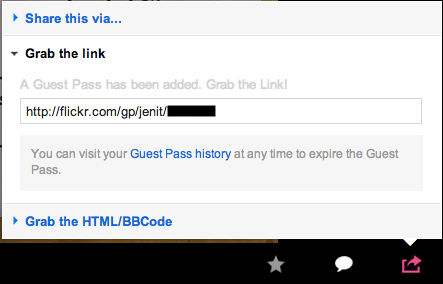
2.6 Flickr images
Private images on Flickr can be shared through Guest Passes which are generated for a given image on demand.
Fig. 6Flickr dialog for a new Guest Pass
Users can view the Guest Pass History which provides the option of expiring the current Guest Pass for the image.
Fig. 7Flickr Guest Pass History
2.7 Tahoe-LAFS
Tahoe-LAFS provides a open cloud storage system that uses capability-based HTTP servers to manage access to files. For example, a URL such as:
provides read-only access to a file stored within Tahoe. The full REST API documentation describes how capabilities such as URI:DIR2:djrdkfawoqihigoett4g6auz6a:jx5mplfpwexnoqff7y5e4zjus4lidm76dcuarpct7cckorh2dpgq are used within URLs and with different HTTP verbs. It distinguishes between file capabilities and directory capabilities, and between read-write, read-only and verify-only capabilities.
3. Reasons to Use Capabilty URLs
There are four rationales for using capability URLs evident in the examples described above.
3.1 No Login Required
A capability URL enables a user to access a service without having a login or password on that service. There are three situations where that is a particular advantage:
users who can't remember login details
users who don't want to create accounts
developers who don't want to support accounts
3.1.1 Forgotten Passwords
Users frequently forget their passwords, especially when their form is restricted based on length or types of characters that they contain. Sending a URL to users who forget their passwords is preferable to sending a password because:
sending a password would require the website to send (and possibly store) the password in plain text, which is a bad security practice
the capability URL can expire after it has been accessed, which means that even if the email or URL is shared later on, it doesn't provide ongoing access to the account
the capability URL can resolve to a page that forces the user to reset their password; if users were simply presented with a password or granted access to the entire system with the URL then they might not remember to reset their password
3.1.2 Low Friction Accounts
There are a proliferation of web-based services which provide for user accounts, to help record user preferences and history. Creating another user account can become a high burden for users, particularly when they don't expect to use the account very frequently.
Web-based applications that do not require user information in order to function may enable users to access the service without creating an account, or only prompt the user to create an account after they have used the service for a while.
Using capability URLs is beneficial to the more regular users of a web-based application because it enables them to collaborate with other people who are not regular users of the service. Regular users can create a resource and share a URL for that resource with their potential collaborators through another route (eg through email).
Capability URLs that are used to facilitate collaboration without requiring accounts are generally controlled by a regular user, who might wish to:
create different capability URLs for different people or groups that they wish to collaborate with
create different capability URLs for different types of action that they wish to permit on a resource (eg editing or commenting or viewing)
be able to revoke permissions for given capability URLs if they learn they have been shared outside the intended group
3.1.3 Websites without Accounts
Account management is seldom the main goal of a web-based application. Although it can be relatively easy for developers to plug in account management, there is an overhead involved: it can raise security concerns, and has legal implications because it involves storing personal data.
In some applications there is no risk of someone else deleting important work belonging to another user. This might be because the web application is not used to do important work. Or it might be that the application does not support destructive acts.
In these cases, it may be that the developer of a web application chooses to use capability URLs rather than supporting user accounts, letting them focus development on the main purpose of the application rather than account management.
3.2 Managing Access on Sandboxed Domains
Sites that host content from untrusted users sometimes sandbox that content within separate per-user domains. This ensures that content managed by users isn't granted the privileges that are usually conferred by being on the same origin.
In these cases, however, access to private content on the user-specific domain cannot be controlled through copying the normal authentication cookies that the user has on the main site, because those cookies would give a route through the sandbox. Instead, per-document capability URLs can provide an alternative authentication mechanism.
Issue 1
I don't think I understand this approach well enough to document it properly. Specifically, given that cookies are domain-specific, I don't understand why copying cookies (for the user on their own domain) isn't a reasonable approach. Or issuing alternative cookies for that domain (effectively forcing them to login twice, once on the main site and once on the user-specific subdomain). Is that just about user experience?
3.3 Easy Delegation
A second set of reasons for supporting capability URLs is that it enables those with whom access is originally shared to continue to share that access with their own network.
For example, if a user is trying to arrange a meeting between organisations, they might not know all the people who should attend the meeting from other organisations. Under a normal account-based method, the user would typically have to gather the information about who should attend the meeting before granting each of those individuals access to the system. With a capability URL, they only have to share the URL with a representative from each organisation, and trust that representative to pass on the URL to whichever colleagues need to take part.
Capability URLs can thus enable permissions to flow through networks more easily than they can with an account-based system.
3.4 Easy Client API
Authentication can be burdensome in HTTP APIs because HTTP is a stateless protocol and requires authentication tokens to be passed and processed on each transaction. This takes up both bandwidth and processing power, which can be a significant overhead for APIs that involve frequent, small, messages.
Capability URLs can be used instead. Clients:
perform authentication as normal
request a list of capability URLs to use for the rest of the session
use those URLs without authentication
This removes the authentication cost on each transaction while keeping the exchanges fairly secure.
Note
There are larger issues here about using HTTP for frequent, small, messages. Arguably, HTTP isn't an appropriate protocol in these circumstances, or other workarounds such as long polling or pipelined requests would work better.
4. Potential Issues
There are disadvantages to using capability URLs arising from the fact that the URLs were not originally designed to contain secret information.
4.1 Risk of Exposure
In general, applications that use URLs are not designed to treat them as sensitive information. URLs appear within URL bars, from which they can be copied by people who see the URL bar (for example during a presentation or over someone's shoulder). They also appear in plain text within application logs, such as within web servers and in browser history.
There are more subtle routes for exposure too. If a link to another site, including automatically followed links such as to images or scripts, is followed on a page accessed through a capability URL, that site may be notified of the capability URL through the Referer HTTP header. Third party scripts within a page accessed through a capability URL can access that URL and potentially record it elsewhere. Hosted services that synchronise browser histories and browser plugin toolbars can easily get hold of URLs for pages that someone using them visits.
The method by which a user gets the capability URL in the first place may also be compromised, enabling an ISP or web-based email service to become aware of the URL. Capability URLs will also be exposed to URL shortening services such as t.co if they are shared via Twitter direct messages.
In browsers where the URL bar also provides access to search, a copied capability URL can be mistakenly be passed through to a search engine, if the browser doesn't recognise that it is a URL (for example because of accidentally added whitespace).
Several browsers detect phishing by sending URLs that are accessed through them back to a central server. As there is no way for a browser to know that a particular URL is a capability URL, these are also sent back to a central server controlled by the browser vendor.
Any of these sources of URLs can be used by search engines and other crawlers, and may therefore result in pages protected through capability URLs being shown within search results.
In short, the risk of exposure of capability URLs can be quite high, particularly when they are accessed through a browser, unless safeguards are put in place.
4.2 Handling Compromises
If a capability URL does leak out to unwanted recipients, the person who originally granted access through that URL needs to be able to revoke it. This is exactly the same as needs to happen in normal account-driven access control. However, capability URLs tend to be designed to be the same for everyone who has the given capability, and therefore revoking the capability URL has an impact on all those who had it. Conversely, in account-based access control it tends to be possible to target the withdrawal of rights on a single user.
It is possible to design systems that use capability URLs in a more targetted way, enabling users to generate multiple URLs for the same capability and to pass those on to different people. This would enable targetted revocation of access rights when a particular URL is compromised.
4.3 Web Architecture
Capability URLs encode a combination of a resource and access privileges for that resource. This leads to separate URLs being used to refer to the same resource (but with different permissions about what can be done with it). For example, Google Calendar provides different URLs for the same iCalendar representation of a calendar for public and private use.
Using multiple URLs for the same resource appears to run contrary to good practice:
Good practice: Avoiding URI aliases
A URI owner SHOULD NOT associate arbitrarily different URIs with the same resource.
However, the main rationale for the recommendation to avoid URI aliases is based on sharing of the URI: it is better for everyone linking to, or talking about, the same resource to refer to it with the same URL, as this creates a more coherent network. Unlike normal URLs, capability URLs are oriented around only limited sharing. In these circumstances, having multiple aliases is not an issue.
What may need to be considered, however, is how to transition from providing access to a resource through capability URLs and taking it public, using a normal URL. This is discussed further in section 5.4Canonical URLs.
4.4 Beyond the Single Page
All the examples of capability URLs described in section 2.Example Capability URLs are self-contained: once a user has accessed a page through a capability URL, they are able to do all they need to do within that page. Capability URLs are less easy to use in applications that require the user to access multiple pages, because each of those pages must be accessed through a URL that contains a different secret.
Tahoe-LAFS uses a pattern whereby directories have capability URLs that grant access to all subresources within that directory, using a pattern like:
To avoid the need for users to log in to perform an action.
To make it easy for those with whom you share URLs to share them with others.
To avoid authentication overheads in APIs.
If you are considering using capability URLs, you should consider other options, and weigh up the costs, risks and benefits of implementing them against the costs, risks and benefits of using capability URLs. For example:
Could access be restricted using an account-based mechanism instead?
Should you use a protocol other than HTTP?
If you have decided to use capability URLs, depending on the level of risk associated with the discovery of a capability URL, you should employ as many of the following security measures as possible:
Capability URLs should be https URLs. This does not prevent all exposure of the URL but does prevent it from being available in plain text within the HTTP request for the URL.
Pages that inform users of capability URLs should be encrypted, by being served through HTTPS. Again, this avoids plain text transmission of the URL.
Capability URLs should expire. For example, it may be suitable to have a capability URL that can only be accessed once, or one that expires after a week. Password reset links should expire after the password has been successfully changed, or when the email address on the account changes.
Pages accessed through a capability URL should not include links to third-party websites, unless the capability URLs include the secret key in the fragment identifier rather than the path of the URL. They should not include a mechanism for others to insert such links onto the page (eg through comments). If these are allowed, the use of the Referer should be managed by:
using rel="noreferrer" on the links
using a Content-Security-Policy: referrer origin HTTP header in the response for the page; none or origin-when-cross-origin could be used instead of origin
using a <meta name="referrer" value="origin"> header within the HTML page; again none or origin-when-cross-origin could be used instead of origin
Pages accessed through a capability URL should not include untrusted third-party scripts, regardless of which part of the URL contains the secret key. Scripts can always get access to the URL of the page they are within.
If capability URLs are controlled by an authenticated user, it should be possible for that user to revoke the capability URLs associated with the resource that they control. They should be able to create multiple such capability URLs so that they can revoke access through a compromised capability URL without affecting access from other capability URLs.
The path under which capability URLs are found should be listed within robots.txt to prevent them from being listed by those search engines that honour robots.txt. Do not list individual capability URLs within robots.txt.
Access to the URL space in which capability URLs reside should be rate limited. This helps avoid attacks that attempt to identify capability URLs by enumerating the possible URLs.
When capability URLs are used, they should be used within an appropriate HTTP verb to enable a relevant action. For example, an HTTP GET on a capability URL should not result in side effects such as the deletion of a resource. Capability URLs should encode access permissions for a resource, not actions on that resource.
Note
Several of these security measures are not possible or inconvenient for capability URLs that are delivered by email. For example, URLs in email can only be accessed through a GET request. It's recommended that those alternative security measures (such as rapid expiry) that can be used are used in these cases.
When capability URLs expire, servers should respond to the URL with either a 410 Gone or a 404 Not Found response. In practice, there is little difference between these responses: a 410 Gone response requires the application to keep track of which capability URLs have been supported in the past; although this is more work for the application, it does prevent the reassignment of that capability URL to a new resource.
5.2 Capability URL Design
Capability URLs must be unique, but they should also avoid being guessable. For example, if capability URLs are generating using a URL like https://example.org/access/{number} and number is merely a sequentially increasing integer, it would be incredibly easy to scan through possible numbers to locate new information.
Good unique URLs include an unguessable unique identifier created through a secure random number generator. If a hash function is used to create the capability URL, for example a hash over a user name for a password reset, these should use an HMAC or other algorithm that is not vulnerable to length extension attacks.
Issue 2
This section needs to include a better discussion of "the appropriate sources of randomness, amount of entropy, signing / expiration algorithms, etc." as pointed out in this post from Michal Zalewski.
There are advantages to making capability URLs short, human readable and case-insensitive, to make it easier for them to be read out, for applications in which delegation is important, and robust against mis-typing. However, capability URLs should not be passed through URL shorteners that have lower protections against enumeration than the original capability URL.
Designing capability URLs to include the secret key in a fragment rather than in the main URL avoids some of the leakage possibilities associated with the Referer header. This is recommended in the web-key proposal. Note however that third-party scripts embedded within pages do have access to full URLs, including the fragment. In addition, this design means that fragment identifiers cannot be used in the normal way for web pages, namely to identify a fragment within the page.
5.3 UI Design Considerations
There is currently no way for built-in user interfaces, such as the location bar of a browser, to detect when a page is being accessed through a capability URL as opposed to a normal URL.
To prevent the capability URL from being visible in the location bar, you can use the replaceState() method to replace the displayed URL with the canonical URL. However, this prevents the capability URL from being bookmarked by the user. In addition, if you do this, you should make sure the capability URL is replaced back into the history when the page is unloaded, otherwise it will not be possible for the user to navigate back to the page by navigating through their history.
Users who are provided with capability URLs to share with others should be informed of the consequences of those URLs being shared widely. Pages should describe what people who get the URL can do with it, and explain the ways in which these URLs can be shared safely.
5.4 Canonical URLs
As outlined in section 4.Potential Issues, servers should have a single canonical URL for a resource when there are several capability URLs that are used to provide access to that resource. This URL may be accessible by users who have the correct access privileges (granted through an account).
Canonical URLs may be used:
to list and provide control over the creation of capability URLs for the resource
as a URL that is transitioned to when a resource becomes public
as a public URL that anyone can access with limited privileges
as a common URL that can be used by anyone in annotations about the resource
If content is served directly from pages accessed through capability URLs, these pages can link to the canonical URL for the resource through rel="canonical" either in the metadata for the page (a <link> element) or within a Link header on the resource.
If the capability URLs refer to a resource that is later made public, they should respond with a 301 Moved Permanently providing a redirection to the normal, public, canonical URL.
A. Future Work
Following the above analysis, the TAG thinks that it would be useful to investigate adding a mechanism to indicate that a particular URL is a capability URL. Possible methods for this include: